想自己做几个聊天机器人,可以在一些开放的话题里进行一些短对话(联系上下文估计还是比较难的)。
- 第一个想做的是可以模拟一个特定的人对话模式的chatbot。比如,在qq上做一个模仿你的机器人�,和朋友说上一二十句话都看不出什么破绽😊。(先从这个练起)
- 第二个是模拟出特定性格人的对话模式的chatbot,比如说按九型人格,或MBTI的人格分类,不同性格的机器人会对同一句话有不同的回答。
- 目前还有一个大胆的想法就是让能不能让机器人从“书籍”里进行学习,比较小孩才是主要从模仿别人对话来学习如何对话,但成人更多是通过阅读来作为说谈的资本。
- 目标:在qq上做一个模仿你的机器人,和朋友说上一二十句话都看不出什么破绽。
- 语料:qq的聊天记录可以直接作为训练的语料,这一点是很方便的。
- 模型:目前不确定,慢慢试试吧,第一篇先从生成式的一些神经网络模型开始探索一下。
- 难点:
- 语料方面,qq聊天中往往不是“一问一答”的,而是多句对多句;语料中还有很多的表情甚至图片视频等多媒体文件,不方便处理;语料中可能会有不少错别字或是谐音字的噪声(比如我,,);个人的语料可能会会不够多。
- qq聊天机器人作为一种“开放话题”和“长对话”场景的机器人,对于目前的前沿研究领域来说本身就还是难题。
- 另外,qq这个软件的对话框不好获取能够输入的接口,不知道能不能解决。
作为聊天机器人的初探,我找了一个完整的项目进行了学习。 见:https://github.com/zhaoyingjun/chatbot
概述
- 目标:qq聊天机器人(生成式;短对话;开放话题)
- 语料:和女友的对话集(大部分都没保存,仅剩7万句)
- 模型:GRU和LSTM(依照zhaoyingjun的项目)
- 技术:seq2seq和word2vec
- 可视化:Flask
数据预处理
数据导入
语料可以直接从qq中把聊天记录导出来(.txt),先删掉[图片],[表情],等这些意义不大的文本,然后进行读取并初步进行处理,把聊天记录分为ask语料集和response语料集,对于多句对多句的问答,这里统一将连续的多句合并为一大句。
conv_path = "meda.txt"
ask = [] # 问
response = [] # 答
one_conv = "" # 存储一次完整对话
f = list(open(conv_path, encoding='UTF-8'))
n = 0
for line in f:
n = n+1
line = line.strip('\n')
if line == '' and flag:
flag = 0
continue
elif ("么大" in line and "-" in line):
nex = f[n]
if nex == "\n":
continue
if len(one_conv):
if meda == 0:
response.append(one_conv)
one_conv = ""
meda = 1
elif "y|c" in line:
nex = f[n]
if nex == "\n":
continue
if len(one_conv):
if meda == 1:
ask.append(one_conv)
one_conv = ""
meda = 0
else:
if len(one_conv):
one_conv = one_conv + " " + line
else:
one_conv += line
flag = 1
语句分词
ask1 = []
response1 = []
for line in ask:
line=" ".join(jieba.cut(line))
ask1.append(line)
for line in response:
line=" ".join(jieba.cut(line))
response1.append(line)
数据清洗
这样依赖剩下三万多句对话,ask集和response集各一半,因为多句的合并,有一些长句,为了简化学习难度,将长句删去。(这里删去超过十个字符的句子)
response2 = []
ask2 = []
for n in range (len(ask)):
if(len(ask[n]) <= 10 and len(response[n]) <=30):
response2.append(response[n])
ask2.append(ask[n])
数据集划分
创建测试集和训练集,直接搬用函数
def convert_seq2seq_files(questions, answers, TESTSET_SIZE):
# 创建文件
train_enc = open(gConfig['train_enc'],'w',encoding='UTF-8') # 问
train_dec = open(gConfig['train_dec'],'w',encoding='UTF-8') # 答
test_enc = open(gConfig['test_enc'], 'w',encoding='UTF-8') # 问
test_dec = open(gConfig['test_dec'], 'w',encoding='UTF-8') # 答
test_index = random.sample([i for i in range(len(questions))],TESTSET_SIZE)
for i in range(len(questions)):
if i in test_index:
test_enc.write(questions[i]+'\n')
test_dec.write(answers[i]+ '\n' )
else:
train_enc.write(questions[i]+'\n')
train_dec.write(answers[i]+ '\n' )
if i % 1000 == 0:
print(len(range(len(questions))), '处理进度:', i)
三分之一作为测试样本
questions = ask2
answers = response2
convert_seq2seq_files(questions, answers, len(ask1)//3)
数据处理器
数据字典
这个函数算法思路会将input_file中的字符出现的次数进行统计,并按照从小到大的顺序排列,每个字符对应的排序序号就是它在词典中的编码,这样就形成了一个key-vlaue的字典查询表。函数里可以根据实际情况设置字典的大小。
# 定义字典生成函数
def create_vocabulary(input_file,output_file):
vocabulary = {}
with open(input_file,'r',encoding='UTF-8') as f:
counter = 0
for line in f:
counter += 1
tokens = [word for word in line.split()]
for word in tokens:
if word in vocabulary:
vocabulary[word] += 1
else:
vocabulary[word] = 1
vocabulary_list = START_VOCABULART + sorted(vocabulary, key=vocabulary.get, reverse=True)
# 取前20000个常用汉字
if len(vocabulary_list) > 10000:
vocabulary_list = vocabulary_list[:10000]
print(input_file + " 词汇表大小:", len(vocabulary_list))
with open(output_file, 'w', encoding='UTF-8') as ff:
for word in vocabulary_list:
ff.write(word + "\n")
seq2seq
这个函数从参数中就可以看出是直接将输入文件的内容按照词典的对应关系,将语句替换成向量,这也是所有seq2seq处理的步骤,因为完成这一步之后,不管原训练语料是什么语言都没有区别了,因为对于训练模型来说都是数字化的向量。
# 把对话字符串转为向量形式
def convert_to_vector(input_file, vocabulary_file, output_file):
print('对话转向量...')
tmp_vocab = []
with open(vocabulary_file, "r",encoding='UTF-8') as f:#读取字典文件的数据,生成一个dict,也就是键值对的字典
tmp_vocab.extend(f.readlines())
tmp_vocab = [line.strip() for line in tmp_vocab]
vocab = dict([(x, y) for (y, x) in enumerate(tmp_vocab)])#将vocabulary_file中的键值对互换,因为在字典文件里是按照{123:好}这种格式存储的,我们需要换成{好:123}格式
output_f = open(output_file, 'w',encoding='UTF-8')
with open(input_file, 'r',encoding='UTF-8') as f:
for line in f:
line_vec = []
for words in line.split():
line_vec.append(vocab.get(words, UNK_ID))
output_f.write(" ".join([str(num) for num in line_vec]) + "\n")#将input_file里的中文字符通过查字典的方式,替换成对应的key,并保存在output_file
output_f.close()
集成函数
这个函数是数据处理器的集成函数,执行器调用的数据处理器的函数也主要是调用这个函数,这个函数是将预处理的数据从生成字典到转换成向量一次性搞定,将数据处理器对于执行器来说实现透明化。working_directory这个参数是存放训练数据、训练模型的文件夹路径,其他参数不一一介绍。
def prepare_custom_data(working_directory, train_enc, train_dec, test_enc, test_dec, enc_vocabulary_size, dec_vocabulary_size, tokenizer=None):
# Create vocabularies of the appropriate sizes.
enc_vocab_path = os.path.join(working_directory, "vocab%d.enc" % enc_vocabulary_size)
dec_vocab_path = os.path.join(working_directory, "vocab%d.dec" % dec_vocabulary_size)
create_vocabulary(train_enc,enc_vocab_path)
create_vocabulary(train_dec,dec_vocab_path)
# Create token ids for the training data.
enc_train_ids_path = train_enc + (".ids%d" % enc_vocabulary_size)
dec_train_ids_path = train_dec + (".ids%d" % dec_vocabulary_size)
convert_to_vector(train_enc, enc_vocab_path, enc_train_ids_path)
convert_to_vector(train_dec, dec_vocab_path, dec_train_ids_path)
# Create token ids for the development data.
enc_dev_ids_path = test_enc + (".ids%d" % enc_vocabulary_size)
dec_dev_ids_path = test_dec + (".ids%d" % dec_vocabulary_size)
convert_to_vector(test_enc, enc_vocab_path, enc_dev_ids_path)
convert_to_vector(test_dec, dec_vocab_path, dec_dev_ids_path)
return (enc_train_ids_path, dec_train_ids_path, enc_dev_ids_path, dec_dev_ids_path, enc_vocab_path, dec_vocab_path)
执行器
具体设置的时候,有两个大原则:尽量覆盖到所有的语句长度、每个bucket覆盖的语句数量尽量均衡。(这个不了解,还没有查到资料,没有做修改)
_buckets = [(1, 10), (10, 15), (20, 25), (40, 50)]
数据读取
读取测试集和训练集
def read_data(source_path, target_path, max_size=None):
data_set = [[] for _ in _buckets]
with tf.gfile.GFile(source_path, mode="r") as source_file:
with tf.gfile.GFile(target_path, mode="r") as target_file:
source, target = source_file.readline(), target_file.readline()
counter = 0
while source and target and (not max_size or counter < max_size):
counter += 1
if counter % 100000 == 0:
print(" reading data line %d" % counter)
sys.stdout.flush()
source_ids = [int(x) for x in source.split()]
target_ids = [int(x) for x in target.split()]
target_ids.append(prepareData.EOS_ID)
for bucket_id, (source_size, target_size) in enumerate(_buckets):
if len(source_ids) < source_size and len(target_ids) < target_size:
data_set[bucket_id].append([source_ids, target_ids])
break
source, target = source_file.readline(), target_file.readline()
return data_set
模型建立
生成模型,模型参数全部单独存储在了seq2seq.ini里
def create_model(session, forward_only):
"""Create model and initialize or load parameters"""
model = seq2seq_model.Seq2SeqModel( gConfig['enc_vocab_size'], gConfig['dec_vocab_size'], _buckets, gConfig['layer_size'], gConfig['num_layers'], gConfig['max_gradient_norm'], gConfig['batch_size'], gConfig['learning_rate'], gConfig['learning_rate_decay_factor'], forward_only=forward_only)
if 'pretrained_model' in gConfig:
model.saver.restore(session,gConfig['pretrained_model'])
return model
ckpt = tf.train.get_checkpoint_state(gConfig['working_directory'])
"""if ckpt and tf.gfile.Exists(ckpt.model_checkpoint_path):"""
if ckpt and ckpt.model_checkpoint_path:
print("Reading model parameters from %s" % ckpt.model_checkpoint_path)
model.saver.restore(session, ckpt.model_checkpoint_path)
else:
print("Created model with fresh parameters.")
session.run(tf.global_variables_initializer())
return model
模型训练
train函数没有参数传递,因为所有的参数都是通过gconfig来读取的,这里面有一个特殊的设计,就是将prepareData函数调用放在train()函数里,这样做的话就是每次进行训练时都会对数据进行处理一次,这个可以保证数据的最新以及可以对增长的数据进行训练,这是很好的设计。
def train():
# prepare dataset
print("Preparing data in %s" % gConfig['working_directory'])
enc_train, dec_train, enc_dev, dec_dev, _, _ = prepareData.prepare_custom_data(gConfig['working_directory'],gConfig['train_enc'],gConfig['train_dec'],gConfig['test_enc'],gConfig['test_dec'],gConfig['enc_vocab_size'],gConfig['dec_vocab_size'])
# setup config to use BFC allocator
config = tf.ConfigProto()
config.gpu_options.allocator_type = 'BFC'
最终对话函数
这个函数就是我们整个对话机器人的最终出效果的函数,这个函数会加载训练好的模型,将输入的sentence转换为向量输入模型,然后得到模型的生成向量,最终通过字典转换后返回生成的语句。
def decode_line(sess, model, enc_vocab, rev_dec_vocab, sentence):
# Get token-ids for the input sentence.
token_ids = prepareData.sentence_to_token_ids(tf.compat.as_bytes(sentence), enc_vocab)
# Which bucket does it belong to?
bucket_id = min([b for b in xrange(len(_buckets)) if _buckets[b][0] > len(token_ids)])
# Get a 1-element batch to feed the sentence to the model.
encoder_inputs, decoder_inputs, target_weights = model.get_batch({bucket_id: [(token_ids, [])]}, bucket_id)
# Get output logits for the sentence.
_, _, output_logits = model.step(sess, encoder_inputs, decoder_inputs, target_weights, bucket_id, True)
# This is a greedy decoder - outputs are just argmaxes of output_logits.
outputs = [int(np.argmax(logit, axis=1)) for logit in output_logits]
# If there is an EOS symbol in outputs, cut them at that point.
if prepareData.EOS_ID in outputs:
outputs = outputs[:outputs.index(prepareData.EOS_ID)]
return " ".join([tf.compat.as_str(rev_dec_vocab[output]) for output in outputs])
可视化展示模块
可视化部分用到了Flask,我还不是特别会,以后在好好学吧,这里就先用了。
app = Flask(__name__,static_url_path="/static")
@app.route('/message', methods=['POST'])
def reply():
req_msg = request.form['msg']
res_msg = '^_^'
print(req_msg)
print(''.join([f+' ' for fh in req_msg for f in fh]))
req_msg=''.join([f+' ' for fh in req_msg for f in fh])
print(req_msg)
res_msg = execute.decode_line(sess, model, enc_vocab, rev_dec_vocab, req_msg )
res_msg = res_msg.replace('_UNK', '^_^')
res_msg=res_msg.strip()
# 如果接受到的内容为空,则给出相应的恢复
if res_msg == '':
res_msg = '什么意思?'
return jsonify( { 'text': res_msg } )
@app.route("/")
def index():
return render_template("index.html")
最终效果展示
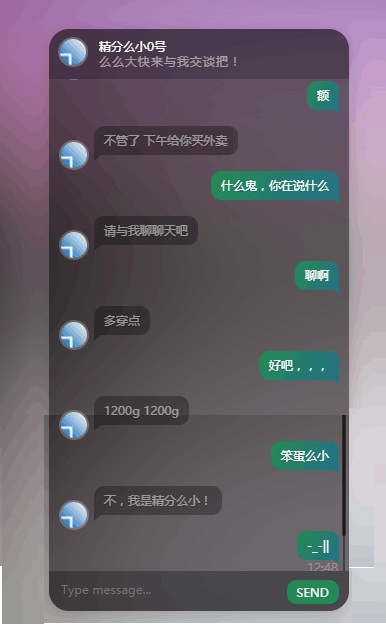
No1 精分的么小
第一次出的结果,留作纪念,可能主要是因为训练时间比较短吧,对话都没有逻辑。把他叫做精分么小。
No2 敷衍的么小
这个训练了十个小时,迭代到40000次,结果,,,
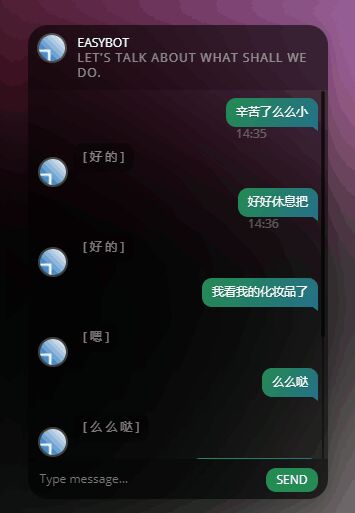
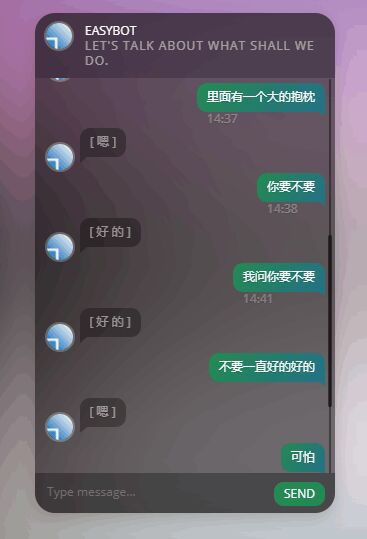
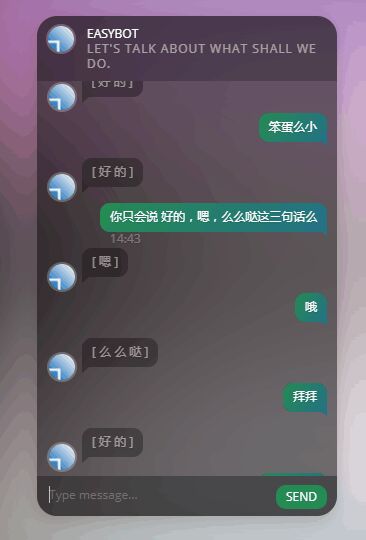
看起来很有道理的样子,有了点“灵性”,不过只会回答三句话(在qq里其实是三种的表情),不过这三句倒是“万能回答”,被AI学习到了。
这还是因为数据量太小(1万句),训练的多了慢慢就“稳定了”,以前就做过一个试验,输入游戏名称和游戏评分作为训练数据,也就是让机器寻找游戏名称和游戏评分的关系,其实这给的信息量就太小了,一个游戏,光从名字能看��出多少东西呢?所以后来发生的情况就是,一开始训练机器似乎还在笨拙的找关系,不同的名称会有不同的分数,但训练次数多了以后慢慢就稳定在了一个分数7分,而统计实际的评价数据中低分和极高分其实都很少,众数也就是7分,于是机器最终找到了这个朴素的答案。
总结
这次算是完整的完成了一个chatbot的小项目,不过这只是第一步,后续的工作还有很多。
- 增加数据集的数量和质量,起码得20万以上
- 对参数进行调优,不过这个在我的小笔记本上时间开销太大了,等到把AWS弄好了,把模型放到网上训练,这个过程就会快多了。
- seq2seq,word2vec,LSTM,GRU对这些方法模型更详细的了解,不过这就很大了,很可能要到读研时再去深入了,现在就作为拾零吧
- 对于这个项目针对qq的聊天机器人,其实应该基于索引的实际效果会更好,接下来在试一下这种实现方法。